Abstract
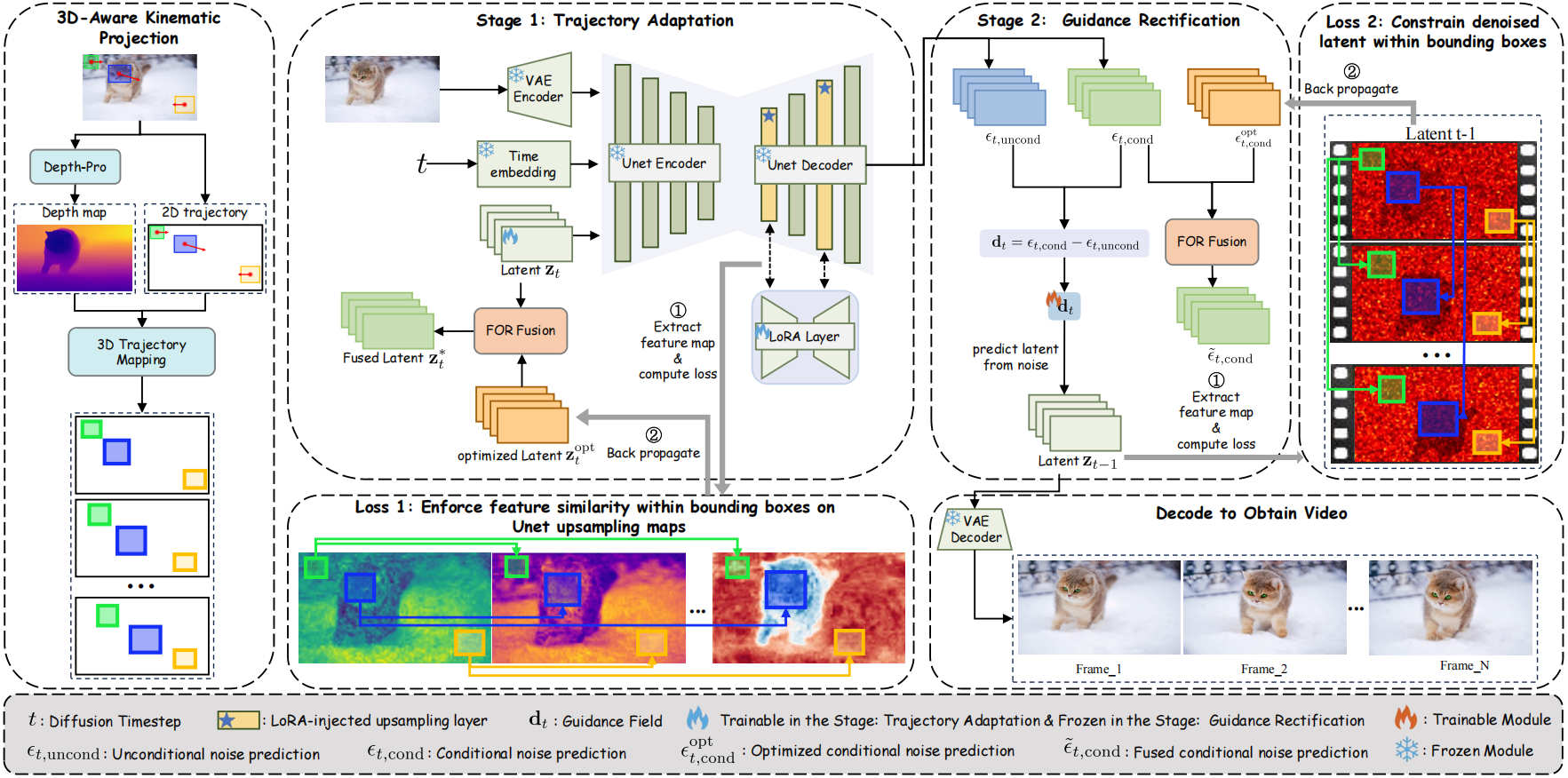
Trajectory-Guided image-to-video (I2V) generation aims to synthesize videos that adhere to user-specified motion instructions. Existing methods typically rely on computationally expensive fine-tuning on scarce annotated datasets. Although some zero-shot methods attempt to trajectory control in the latent space, they may yield unrealistic motion by neglecting 3D perspective and creating a misalignment between the manipulated latents and the network's noise predictions. To address these challenges, we introduce Zo3T, a novel zero-shot test-time-training framework for trajectory-guided generation with three core innovations: First, we incorporate a 3D-Aware Kinematic Projection, leveraging inferring scene depth to derive perspective-correct affine transformations for target regions. Second, we introduce Trajectory-Guided Test-Time LoRA, a mechanism that dynamically injects and optimizes ephemeral LoRA adapters into the denoising network alongside the latent state. Driven by a regional feature consistency loss, this co-adaptation effectively enforces motion constraints while allowing the pre-trained model to locally adapt its internal representations to the manipulated latent, thereby ensuring generative fidelity and on-manifold adherence. Finally, we develop Guidance Field Rectification, which refines the denoising evolutionary path by optimizing the conditional guidance field through a one-step lookahead strategy, ensuring efficient generative progression towards the target trajectory. Zo3T significantly enhances 3D realism and motion accuracy in trajectory-controlled I2V generation, demonstrating superior performance over existing training-based and zero-shot approaches.
Pipeline Framework